MBDPO: Scaling World-Model Reinforcement Learning Through Diffusion Policy Optimization
Abstract
MBDPO is a model-based reinforcement learning framework that unifies search and policy optimization through a diffusion policy inside a learned latent world model. Instead of placing an explicit planner such as MPPI on top of the world model, MBDPO reformulates policy optimization as a diffusion process over imagined trajectories, where the score field is corrected by model-based returns and anchored to the behavior distribution via an implicit energy function. This eliminates the structural misalignment between search and value learning that limits prior world-model approaches, and yields monotonic scaling of performance with model capacity.
Why Scaling World-Model RL Remain Hard?
Scaling world-model RL is not limited only by model prediction error. A deeper bottleneck is the mismatch between how actions are selected by search and how values are learned from replay data: the planner may move toward actions where the learned value function is unreliable, causing value overestimation and unstable policy improvement.
World-Model Score Correction
MBDPO uses imagined rollouts in the latent world model to evaluate candidate action sequences and correct the diffusion score toward higher-return behaviors.
Implicit Energy Anchor
MBDPO learns an implicit energy function from replay data to anchor the policy to the behavior distribution, preventing drift toward unreliable high-value regions.
Diffusion Policy
MBDPO represents policy improvement as iterative denoising over future action sequences, turning search into a learnable policy optimization process.

Model-Based Diffusion Policy Optimization (MBDPO)
Strong Performance Across Online, Offline, and Fine-tuning

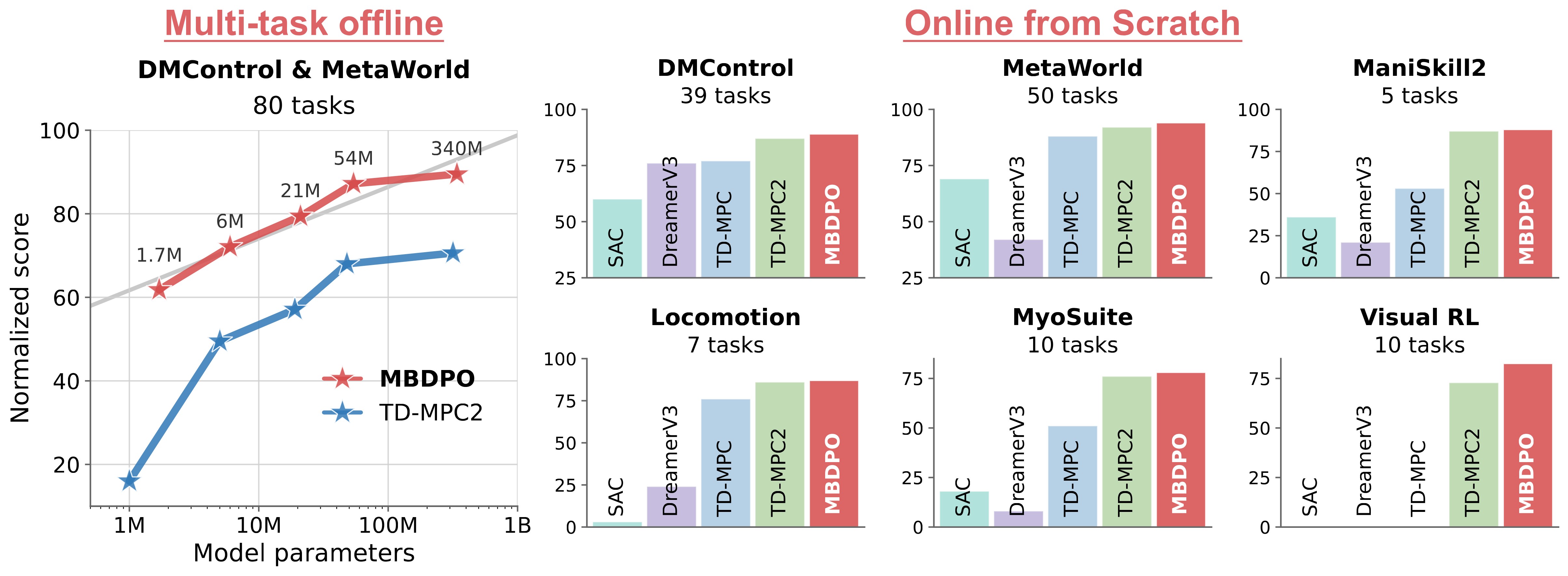
MBDPO achieves strong online-from-scratch performance across diverse control suites. Compared with SAC, DreamerV3, TD-MPC, and TD-MPC2, MBDPO learns faster and reaches higher or competitive final performance across state-based, visual, locomotion, manipulation, and musculoskeletal control tasks.
Monotonic Scaling in Offline Pretraining
MBDPO shows monotonic performance gains as model capacity increases from 1.7M to 340M parameters, outperforming TD-MPC2 across model scales in multi-task offline pretraining.
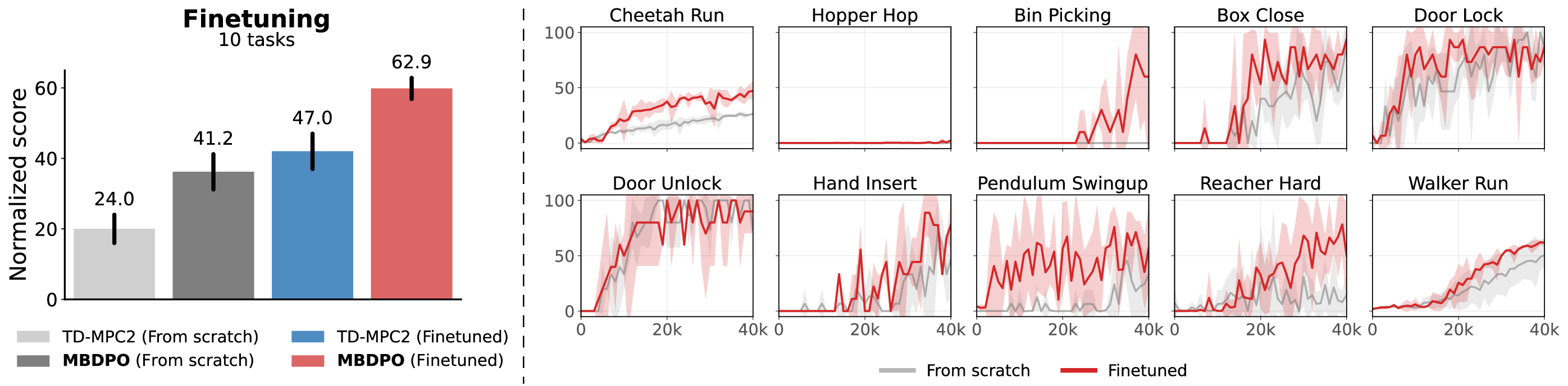
Offline-to-online fine-tuning transfers a pretrained generalist agent to unseen tasks with limited interaction. With only 40K online steps per task, MBDPO fine-tuning substantially outperforms training from scratch, demonstrating efficient adaptation from pretrained world-model representations.
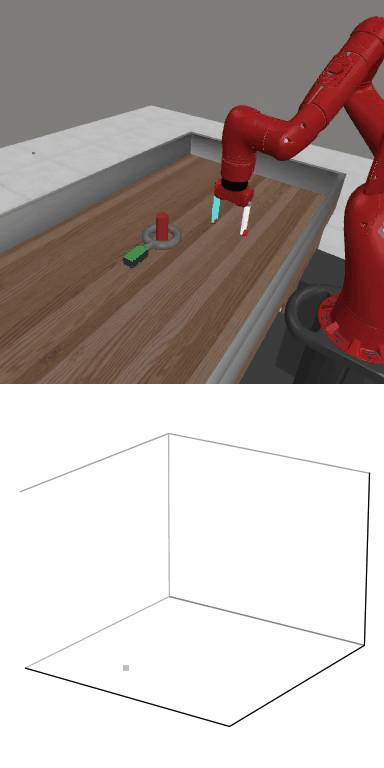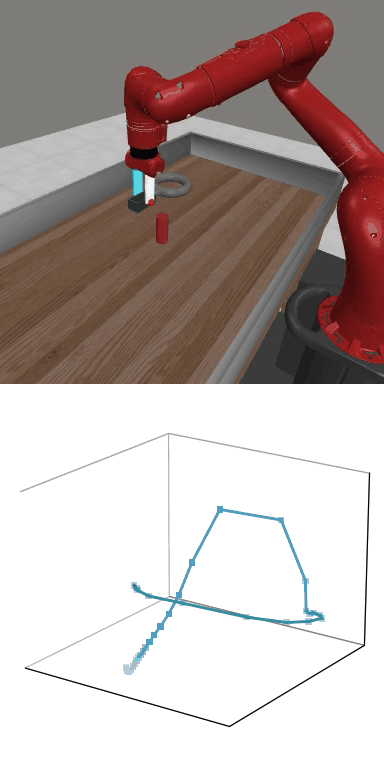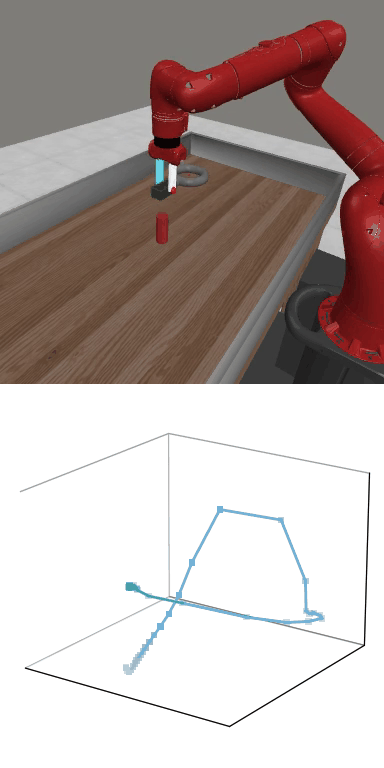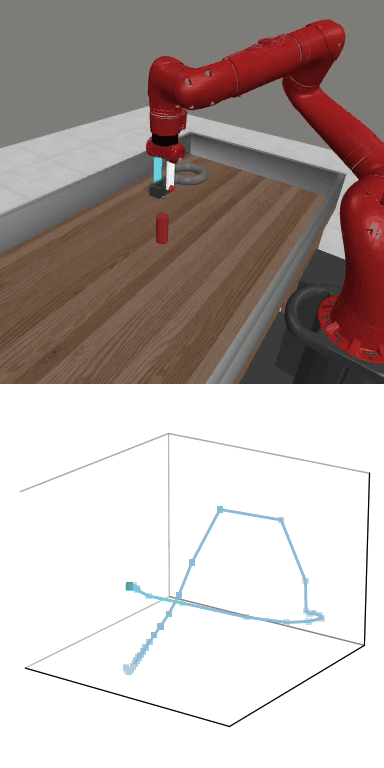
MBDPO produces structured latent trajectories that align with task dynamics. Cyclic control tasks form closed-loop patterns, while manipulation tasks follow directed paths toward the goal, suggesting that the learned world model supports physically meaningful policy optimization.
Structured Latent Trajectories
MBDPO learns latent trajectories that reflect the structure of the underlying control task. Cyclic skills form closed-loop patterns, while goal-directed manipulation tasks produce smooth trajectories from initial states to successful completion.
 Reward: 740.7
Reward: 740.7
 Reward: 840.4
Reward: 840.4
 Reward: 985.0
Reward: 985.0
 Reward: 769.2
Reward: 769.2
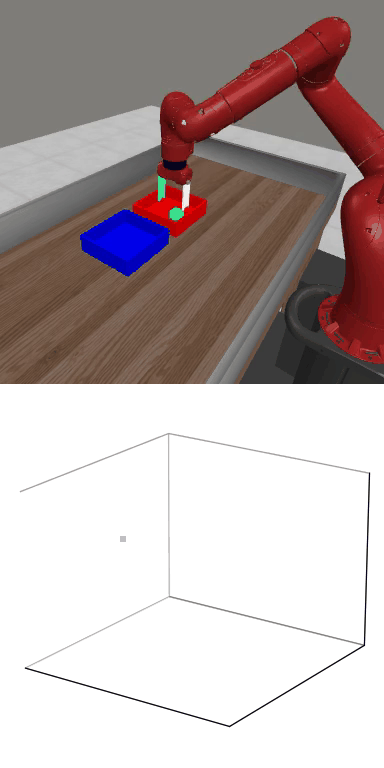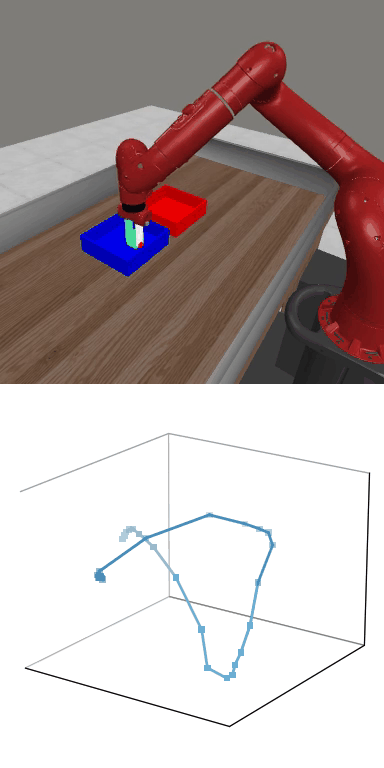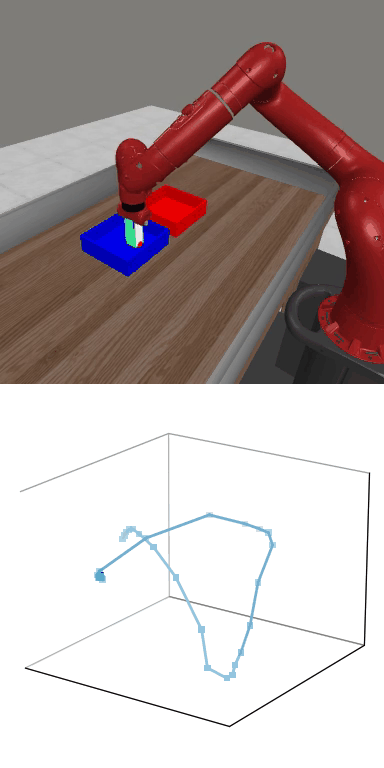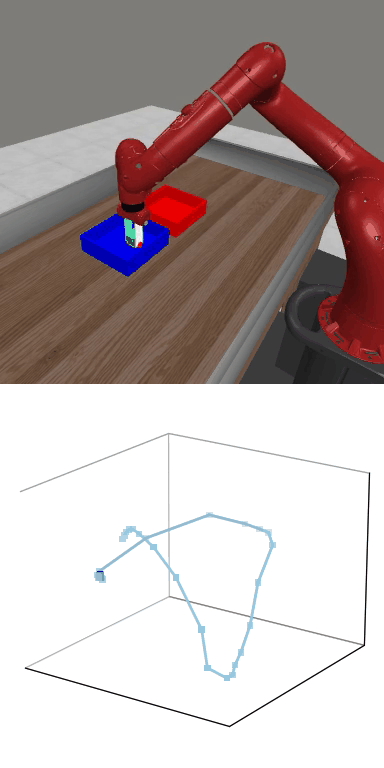 Reward: 1585.0
Reward: 1585.0Success Rate: 1.00
 Reward: 1556.2
Reward: 1556.2Success Rate: 1.00
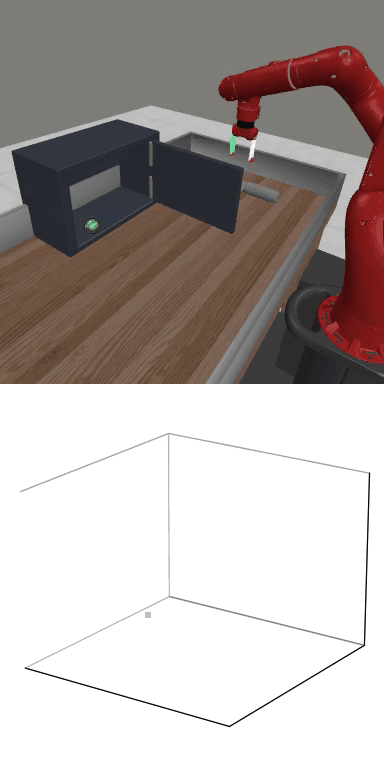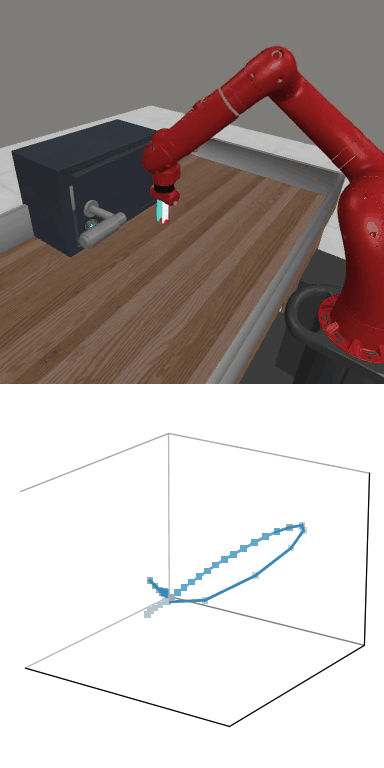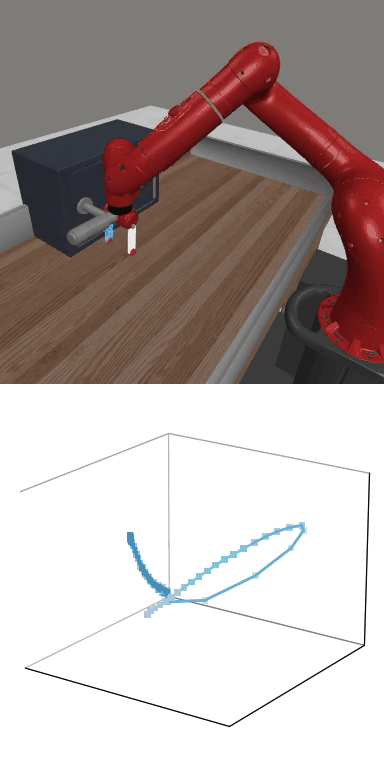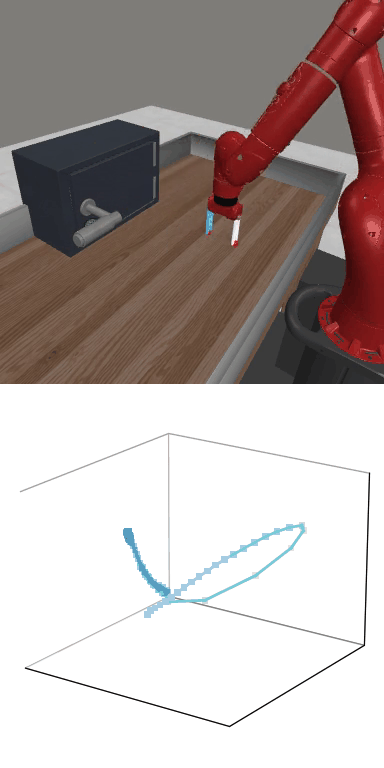 Reward: 1549.1
Reward: 1549.1Success Rate: 1.00
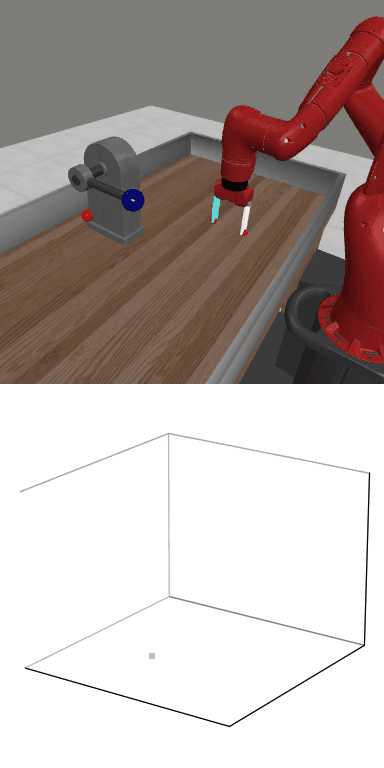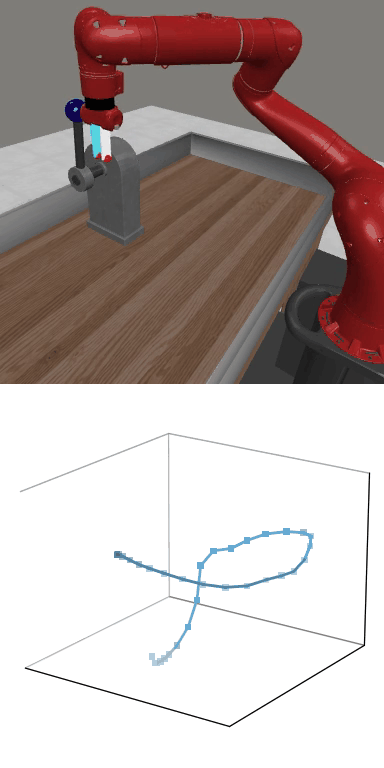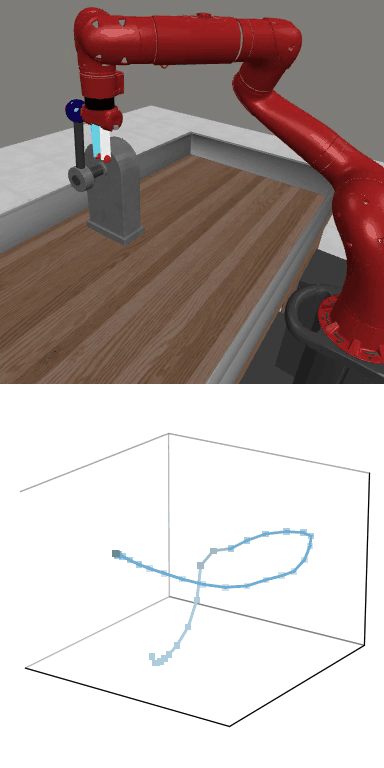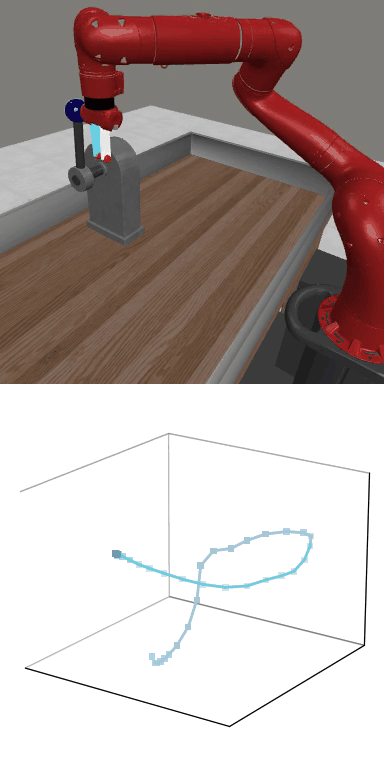 Reward: 1664.9
Reward: 1664.9Success Rate: 0.90
BibTeX
@misc{cheng2026scalingworldmodelreinforcementlearning,
title={Scaling World-Model Reinforcement Learning Through Diffusion Policy Optimization},
author={Xiaoyuan Cheng and Wenxuan Yuan and Zhancun Mu and Yuanzhao Zhang and Yiming Yang and Hai Wang and Zhuo Sun and Che Liu},
year={2026},
eprint={2605.26282},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={http://arxiv.org/abs/2605.26282}
}